About Me

Thrive to be a full-stack data scientist who can conduct rigorous research to uncover business insights and also deliver production-level code to build practical applications.
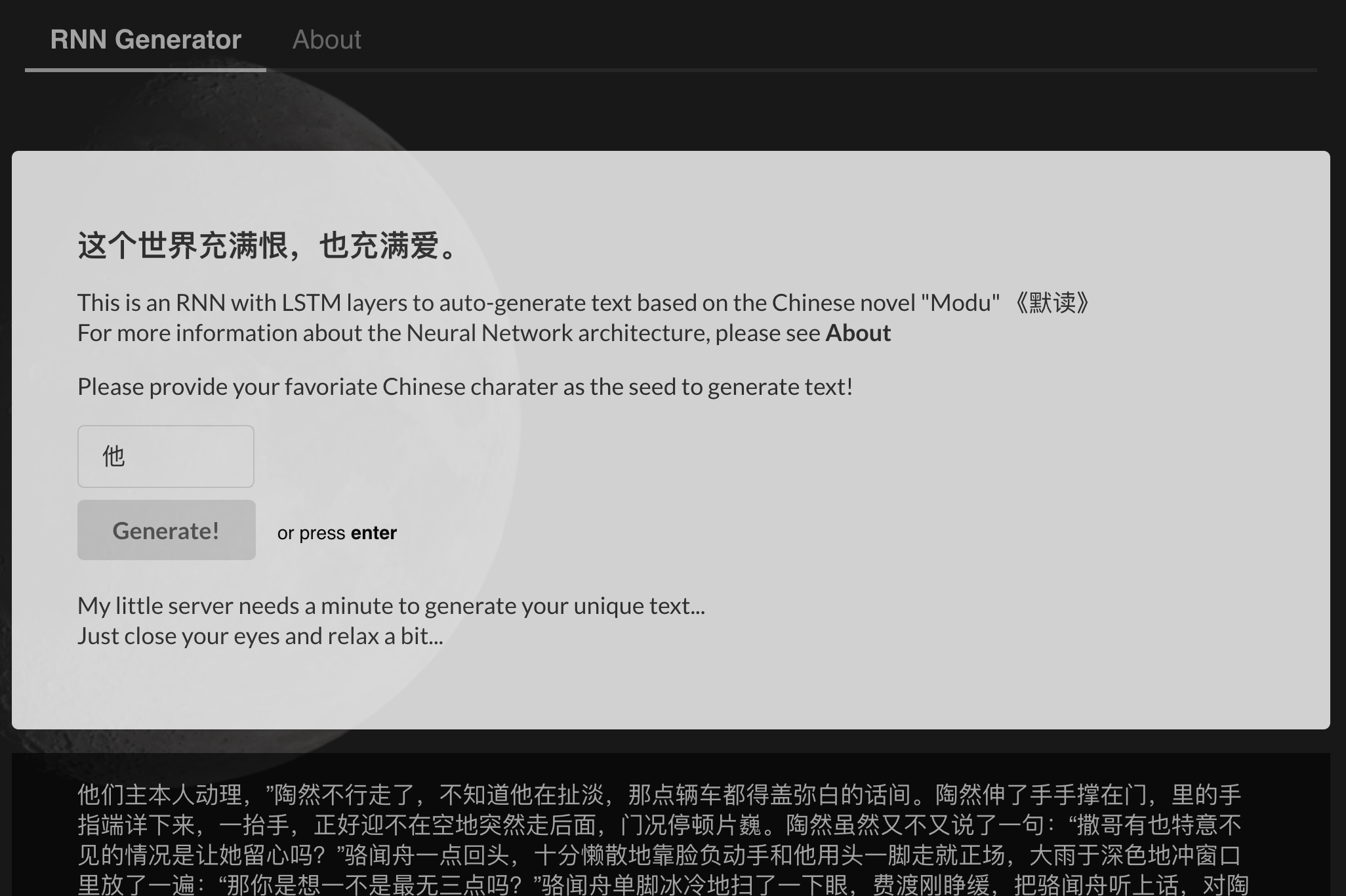
I'm Yingchi, born in China and currently working as a data scientist at Indeed, Singapore. I specialize in building production-level data science solutions with big data environment, with familiarity and hands-on working experience with classical ML methods like Logistic Regression, Random Forest, Boosting, NLP techniques and Neural networks.
Topics of interest: text mining, recommendation, neural network and more...
I love taekwondo 🥋, piano 🎹 and ice cream 🍦. And I'm keen to learn, experience and share.